Tangles of Personality Traits
This page is a read-only extract from an interactive tangle software tutorial, with the same title, which is offered in the form of a jupyter notebook on our GitHub page. The steps required to run it are described there, in the 'getting started' section.
The tutorial assumes that readers have an intuitive understanding of mindset tangles as described in the introductory Chapter 1.2, Tangles in the social sciences, of Diestel's Tangles book. Other relevant chapters from the book, not required reading for this tutorial, are:
- Chapter 5, a collection of intuitive examples of mindset tangles in different applications;
- Chapter 7, the reference chapter for the mathematical definitions associated with tangles;
- Chapter 13, which revisits the examples from Chapter5 to give a more mathematical discussion of mindset tangles.
The survey we analyse here is a diagnostic survey used in personality assessment. Thus, our tangles do not represent mindsets in the informal sense of the word, but in this case capture personality types. We still refer to them as mindsets, the term used generically in the book for survey-based tangles of this kind.
Our diagnostic survey is based on the five-factor model of personality, also known as the OCEAN model or simply as the 'Big Five'. This model proposes that a person's personality can be assessed comprehensively by measuring to what degree they have the following five traits:
- E for extraversion
- N for neuroticism
- A for agreeableness
- C for conscientiousness
- O for openness to experience
We used data from here; follow the link 'BIG5'.
There are ten statements for each of the five traits E, N, A, C and O (details), statements in total. Each statement is rated by the participants on a scale from 1 (strongly disagree) to 5 (strongly agree).
Before we present our results, let us repeat that our focus here is on demonstrating the potential of our tangle software library. While our results may already be interesting, they are not meant to be an exhaustive survey analysis.
Surveys and features
For each statement in the survey we define two features: that of agreeing with the statement, and the inverse feature of disagreeing with it. Here we say that a participant agrees with a statement if their (normalised) rating of the statement is greater than the median of all the ratings of that statement returned by the participants of the survey.
This is but one of many options of turning survey questions into features. Other ways to do this may lead to different results. This is an important benefit of the tangle search process: it opens up many options for the user to customize their analysis.
We used the tangle library to find tangles on this set of potential features. Each of these tangles thus represents a 'mindset': one way particular way of agreeing or disagreeing with each of the statements that is typical for the returns for this survey.
The tangles, or mindsets, we found all answer each group of questions that targeted the same of the 'big five' personality traits in essentially just one way: they did not differ much within any of those five sets of questions. This confirmed that the questions within each group were well chosen in the sense that they each identify one and the same trait, whatever this may be.
The tangles we found on all the questions can therefore be summarized by their uniform answers to each of those 5 groups of questions: they are essentially one way of answering five questions, not.
The table shows the most distinctive tangles, or mindsets, we found. Each row represents one mindset.
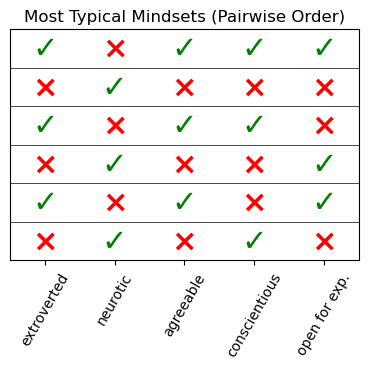
If we have a closer look, we notice an interesting detail: the inverse of each of the six mindsets we found is itself a mindset. That is not normally the case; it is a first insight at the interpretation level.
Typical ranges of ratings
In the last section we defined one potential feature for each statement. For each participant, this gave us one true/false value for each of the 50 statements.
We now refine this approach, as follows. For each statement we create not one but four potential features. Their positive specifications are as follows:
Note that the specification of is included implicitly here as the negation of.
When we compute tangles for our now potential features we seek to specify the most significant of these first. This ranking of significance comes from what the tangle book calls an 'order function' on the set of all potential features. Our computations here use an entropy-based order function (see Chapter 9).
Every tangle that specifies such a subset of our potential features associates with every statement a rating interval of, as follows. Suppose it contains, for some fixed as above, and, the negation of, and does not specify or. This assigns to a rating of at least3 and at most, i.e., the interval.
The table below shows seven tangles found on a set of potential features of low order. Each row depicts one tangle. For each column, which corresponds to a potential feature, it shows the interval it assigns to that to that interval . The colours reflect the answers given, from dark red for 'strongly disagree' via yellow for 'undecided' to dark green for 'strongly agree'.
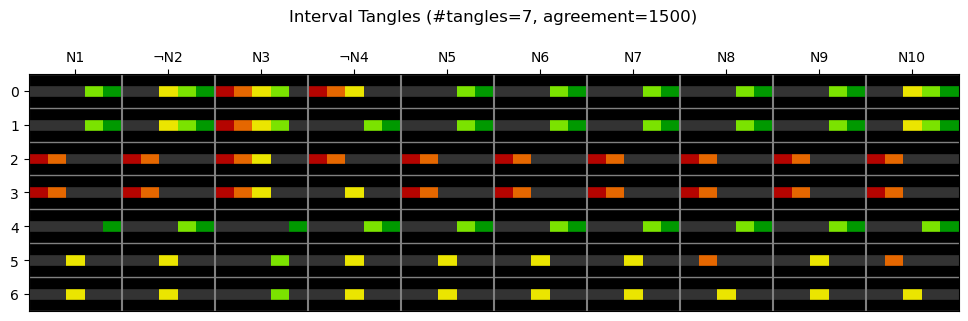
Let us now turn to interpretation. The statements , which our order function selected as the most significant ten statements, were as follows:
- N1 I get stressed out easily
- N2 I am relaxed most of the time (reversed)
- N3 I worry about things
- N4 I seldom feel blue (reversed)
- N5 I am easily disturbed
- N6 I get upset easily
- N7 I change my mood a lot
- N8 I have frequent mood swings
- N9 I get irritated easily
- N10 I often feel blue.
We can recognize three groups of tangles:
- Tangles 5, 6: These tangles specify a single rating value for each statement. Interestingly, these tend to be moderate ratings.
- Tangles 2, 3: We see two mindsets not showing a neurotic tendency:
- Tangle 2 is straightforward. All statements get a low rating.
- Tangle 3 represents participants that don't have typical neurotic character traits but feel blue at times.
- Tangles 0, 1, 4: These are the most typical ways of how participants that do tend towards neuroticism rate the statements.
- Tangle 4 is straightforward.
- Tangle 1 represents participants that are neurotic, but say they don't worry too much about things.
- Tangle 0 is similar, but represents participants that feel blue less often than most participants with a neurotic tendency.
Note an unexpected detail concerning tangle0: while ¬N4 has a low to medium rating, N10, which should be equivalent to¬N4, has a medium to high rating. It may be interesting to look further into the relation of ¬N4 and N10 ratings.
Our tutorial ends here. It was meant to indicate in the most rudimentary of ways how tangles can be found in data, and what their interpretation might look like. On larger and more varied surveys one can find more tangles, and then relate these to each other as explained in Chapters 7.4 and8.2 of the tangles book.